We’ll begin with a brief survey of a problem raised by Derek Parfit about the nature of personal identity, then we move swiftly to consider whether such problems can motivate a plurality of distinct existential quantifiers and orders of explanation.
The question of personal identity begins with a thought experiment. Imagine teleportation technology exists such that entry into a teleportation pod involves the slow destruction of your physical body (through radiation poisoning) and the (immediate) reconstruction of an identical healthy body within another pod at the destination. The process is such that upon reconstruction, the individual at the destination has retained all of your physical and mental characteristics, they have your memories, instincts, attributes and desires. The question remains; are you dead and cloned or alive and arrived?
Two Criteria of Personal Identity
The first criterion we shall examine is the notion that identity is determined by physical continuity. The intuition is best compounded by insight that a white billiard ball can undergo a cosmetic change by being painting red. Another comment on cosmetic alterations gives the lie to idea that any significant change has occurred. You can put lipstick a pig, but it remains a pig regardless. This image is somewhat more visceral, but the same idea underwrites both scenarios. That said, there are some complications in the case of personal identity. If your identity is fully and only determined by your physical constitution, then is there a point of physical change which would constitute a shift in personal identity? Suppose that your beliefs, desires, memories and intentions are fully fixed by an arrangement of brain states, then can brain damage impact the existence of your person-hood? Parfit glosses these concerns as follows:
What is necessary [for personal identity] is not the continued existence of the whole body, but (1) the continued existence of enough of the brain to be the brain of a living person. X today is one and the same person as Y at some point in time if and only if (2) enough of Y’s brain continued to exist, and is now X’s brain and (3) this physical continuity has not taken a “branching” form. (4) Personal identity over time just consists in the holding of facts (2) and (3).
We say an object’s continuity takes a branching form if the same physical continuity can be ascribed to more than one object. For instance if at some point an object is disassembled and then later two objects are assembled physically identical to initial object. Hence if we take physical continuity in this sense as a measure of personal identity then the teleportation thought experiment involves little more than death and cloning, without a preservation of personal identity. The same physical continuity can be ascribed to myself and my clone for the brief time in which we exist simultaneously.
If instead we look to the psychological criterion of personal identity things are a little more subtle. Here the idea that is personal identity involve a certain kind of psychological connectedness over time. Again you might think brain damage is a concern where amnesia could sufficiently devastate the concepts of self, desires and belief in such a way as to entirely destabilize the psychological connectedness for an individual between two points 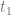 and
and  . So construed the core issue is that of the stability of a psychological connectedness over time. The loss of such connectedness is arguably recoverable if the condition impacting your sense of self, belief and desires is medically induced. In a very real sense you can take time off from yourself if you’re prepared to indulge in sufficiently mind altering drugs.
. So construed the core issue is that of the stability of a psychological connectedness over time. The loss of such connectedness is arguably recoverable if the condition impacting your sense of self, belief and desires is medically induced. In a very real sense you can take time off from yourself if you’re prepared to indulge in sufficiently mind altering drugs.
Distinguish between your sense of self yesterday and the sense of self you had when four, and so note that we need to distinguish the strength of the relation for psychological connectedness. Let’s define a notion of psychological continuity in terms of overlapping links of strong psychological connectedness. Whatever the locus of our sense of self, there are experiences which cause the generation of such a feeling, that nevertheless diminishes over time. So with this in mind Parfit puts forward the following suggestion:
There is a psychological continuity if and only if there are overlapping chains of strong connectedness. X today is one and the same person as Y at some past time if and only if (1) X is psychologically continuous with Y, (2) this continuity has the right kind of cause, (3) it has not taken a “branching” form. Personal identity just holds in satisfying (1) – (3).
The “right kind of cause” is deliberately ambiguous since the explanation of subjective self experience is not yet well understood in terms of the physical neuro-chemical description of psychological states. For discussion see here. The physical criterion ensures that there is no such thing as personhood over and above physical continuity, while the psychological criterion is more ontologically generous, but both of these characterizations are to be considered provisional as we will come to reconsider the importance of non-branching continuity. For the moment, note that the psychological criterion allows that there is such a thing as personhood for particular individuals in absence of physical continuity if the psychological state transfers over teleportation. This gels well with legal description of individuals within a state body who are ascribed rights after physical death and incineration. But is there something fanciful and needlessly metaphysical about such a view? Are persons merely a necessary fiction motivated to supply lawyers with clients?
Fundamentality: Restricted or Generic Quantification
Traditional existential claims have been considered univocal. There is (it’s often assumed) very little ambiguity attached to existential claims. However, if we accept that persons exist over and above their physical instantiation, then there seems to be a distinction between the claim that  where
where 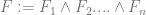 is a complex descriptive predicate circumscribing the location and physical continuity of the individual over time, and the claim that
is a complex descriptive predicate circumscribing the location and physical continuity of the individual over time, and the claim that 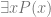 where
where  is the “…is a person” predicate. Now since the quantifier ranges over a given domain, we ought to consider the components of that domain. In particular, we ought to consider whether the domain of quantification contains persons fundamentally , or whether personhood is some kind of abstraction over and above observations of kinds of continuity amongst more primitive physical/psychological states?
is the “…is a person” predicate. Now since the quantifier ranges over a given domain, we ought to consider the components of that domain. In particular, we ought to consider whether the domain of quantification contains persons fundamentally , or whether personhood is some kind of abstraction over and above observations of kinds of continuity amongst more primitive physical/psychological states?
On the assumption that existential claims are univocal, then the contention that persons exist is exactly the claim  . However, if we wish to distinguish between the physical ontological primitives and persons, then personhood can be identified with a property described in physical terms akin to the claim that
. However, if we wish to distinguish between the physical ontological primitives and persons, then personhood can be identified with a property described in physical terms akin to the claim that 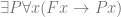 , but this arguably reverses the order of definition. We might instead accept the existence of persons and seek to explain their occurrence.
, but this arguably reverses the order of definition. We might instead accept the existence of persons and seek to explain their occurrence.
If we start with primitive restricted quantifiers and the assumption that existence claims are polysemous, then we make sense of the idea that claims about the existence of God and the existence of the Pope involve distinct considerations of proof and evidence. With this in mind you might want to distinguish between the generic existential quantifier which covers both God and his mouthpiece; 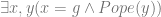 and the restricted quantifiers for abstractions and concrete entities:
and the restricted quantifiers for abstractions and concrete entities:  . Further fine grained distinctions could be made, if for instance you wanted to mark the difference between legal and mathematical abstractions or biological and chemical entities. On a purely semantic understanding the generic quantifier can be as readily understood as the disjunction of the more restricted quantifiers or the restricted quantifiers can be understood (unsurprisingly) as the restriction of the generic quantifier. But if we allow that the restricted quantifiers are ontologically more primitive such that we have
. Further fine grained distinctions could be made, if for instance you wanted to mark the difference between legal and mathematical abstractions or biological and chemical entities. On a purely semantic understanding the generic quantifier can be as readily understood as the disjunction of the more restricted quantifiers or the restricted quantifiers can be understood (unsurprisingly) as the restriction of the generic quantifier. But if we allow that the restricted quantifiers are ontologically more primitive such that we have 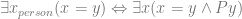 as ontologically basic and semantically uncontested then it is a discovery that there exists a property definitive of person hood i.e. that
as ontologically basic and semantically uncontested then it is a discovery that there exists a property definitive of person hood i.e. that  Minimally I take it that this approach better fits with the natural ontological attitude.
Minimally I take it that this approach better fits with the natural ontological attitude.
The vocabulary in which  is defined can be more or less ontologically primitive than the “personhood”-vocabulary. The desire to streamline our ontological concerns would involve subsuming (by means of structurally relating) the entities of the higher-order ontologies within the class of entities definable in terms of ontological primitives. We currently have a structure something like the following:
is defined can be more or less ontologically primitive than the “personhood”-vocabulary. The desire to streamline our ontological concerns would involve subsuming (by means of structurally relating) the entities of the higher-order ontologies within the class of entities definable in terms of ontological primitives. We currently have a structure something like the following:
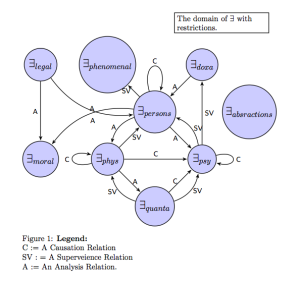
In this map I have supplied a tentative categorization of the relations between some existential domains; linking the physical and psychological domains with the quantum level, and allowing the domain of persons to arise from characterisations in both the more primitive domains. The general point is that if we can define the property in terms of physical and relational predicates describable in the vocabulary of physics and neuro-chemistry then we have established a translation manual between the two domains of ontological concern. But many such translation manuals can be defined. For instance, instead of defining a person in terms of their physical constitution and continuity, we might seek to define a person in terms of their moral responsibilities in domain where individual rights, obligations and moral actors exist. The instinct to reconcile two such domains is common because we seek simplicity, but reconciliation is not necessarily possible. Some questions naturally arise: Do we need reconciliation? Is there an infinite plurality of nested ontological quantifiers? Can we reduce each claim in some ontological domain 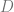 into equivalent claims in another ontological domains
into equivalent claims in another ontological domains  perhaps more primitive? How are the ontological domains ordered? Is there any partial overlap between domains that would make existential claims directly ambiguous? Are some ontological domains simply mutually exclusive? Should this incompatibility trouble us?
perhaps more primitive? How are the ontological domains ordered? Is there any partial overlap between domains that would make existential claims directly ambiguous? Are some ontological domains simply mutually exclusive? Should this incompatibility trouble us?
A Case for Univocal Existential Quantification
But before considering these questions you might object that our notion of a plurality of quantifiers is entirely bankrupt! One such argument from Peter van Inwagen purports to show that existence must be univocal. The main premise of the argument is that the notion of existence is related to number, and the argument stems from the fact that number is univocal. To see this first consider how an existential claim relating to a particular entity is just the assertion that the number of said entities is positive. Now compare the number of gods and the number of round squares. The number is identical since none exist. More positively, the number of horses is not zero, is equivalent to the claim that horses exist. In other words, define a predicate  , then:
, then:
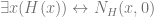
Hence, by translation and the fact that numeric statements are not ambiguous the notion of existence cannot be polysemous. This argument is based on the view that extensional equivalence underwrites all semantics. However, if we argue that the polysemous nature of the existential quantifier depends on an intensional variance, then no such conclusion follows. However such a route undermines the idea of de re ontology we are engaged in. Nevertheless, we do not need to be concerned by the argument, because we can tolerate the idea that the notion of existence comes in the form of generic and restricted quantifiers, where the domain of the restricted quantifier is a proper subclass of the domain of the generic existential quantifier. The behavior of the semantics for 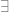 will not change, but the open question for any candidate ontological domain which falls under a restricted quantifier
will not change, but the open question for any candidate ontological domain which falls under a restricted quantifier  , is whether this domain can be fitted into our best theory of world. Does the ontological structure of a theory in which is included, carve the world at the joints? If not, are there more pragmatic reasons for maintaining the theory with its current ontological baggage?
, is whether this domain can be fitted into our best theory of world. Does the ontological structure of a theory in which is included, carve the world at the joints? If not, are there more pragmatic reasons for maintaining the theory with its current ontological baggage?
No matter how we would seek to define personhood we need to invoke the existence of a property, such that the second order quantifier is appropriately indexed to a base vocabulary in which our candidate definition is expressible. So assuming there is a good candidate expressed in terms of psychological/physical continuity, we would have something like: 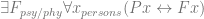 . The challenge is to discover the existence of and thereby clarify the structure in which the ontological domains are ordered. Until such a time as the structure has been delineated what cause have we to assume the character of such an ordering will ultimately see personhood defined in terms of a psychological or physical continuity? The broader moral is that the semantics for “existence” can be seen to evolve with the structure of available theory, the semantics for the generic is as liberal as the disjunction of its sub-domains allows.*
. The challenge is to discover the existence of and thereby clarify the structure in which the ontological domains are ordered. Until such a time as the structure has been delineated what cause have we to assume the character of such an ordering will ultimately see personhood defined in terms of a psychological or physical continuity? The broader moral is that the semantics for “existence” can be seen to evolve with the structure of available theory, the semantics for the generic is as liberal as the disjunction of its sub-domains allows.*
Permissive Ontologies?
While our characterization of the discipline of ontology might seem to be overly permissive, we shall show that the concern for internal consistency is as pertinent as ever, thus providing a restriction on the plurality of entities admitted by our best theory. Staying with the subject of personhood we consider an argument against cartesian dualism and the ontology of separately existing mental entities.
The idea is that there is a unified subject of experience, a distinct entity – the referent for every use of the term “I”. This entity is who I am but exists over and above my physical instantiation. How can we argue for the existence of such a creature? The standard Cartesian argument that “I think therefore I am” is less than decisive since the possibility of thought presupposes the existence of a thinker, but not the character of the thinking agent. Even if the subjective unity of experience, the coherence of appearance in each instance allowed us to identify ourselves as the subject of that experience, we could not ensure that this subject of experience continued to exist moment after moment. The sense of self which accompanies the immediate experience does not imply the persistence of the subject of experience. At best we are aware of the psychological continuity in terms of our memories of our attitudes and desires over time. Hence the Cartesian subject is an extraneous somewhat poorly motivated ontological posit.
Worse Descartes’ cogito observation at best illustrates that thinking occurs, but it is only a contingent fact that we ascribe thoughts to thinkers. Strictly speaking we could eliminate talk of thinkers is if we could locate thoughts in an impersonal level of description, such as brain activity. Consider Parfit’s reincarnation argument. If a Japanese woman had verifiable memories of her life as a Celtic warrior, then we should distinguish between beliefs as carriers of memories in a brain, and beliefs proper, perhaps as ideas in the mind of a Cartesian subject. The reincarnation possibility would provide evidence for the existence of the Cartesian subject, but it depends on the viability of verifying the reincarnation possibility. Similar remarks apply to cases of brain damage which should (given all we know about memory retainment) wipe the memories from the mind of an individual but for some reason as yet undiscovered do not. Both these possibilities are implausible and the latter points, at worst, only to a gap in our knowledge of the brain, not the need for Cartesian dualism.
So what then does the term “I” refer to? Does the term have extension in the domain of the 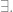 quantifier? The simple answer is yes, if the domain contains a restriction for the class of persons. The answer is a little more complicated if we do not allow this simplification. Nagel, for instance, takes the extension of the term “I” to be exactly the brain of each individual. But we can consider a kind of Kantian argument that the notion of personhood is indispensable to our conception/knowledge of the world. Everything we know about about the world is filtered or mediated via our position in the world i.e. specified in relation to the type of entity we take ourselves to be. Hence any knowledge we have of the world is impossible without the supposition of personal identity. The premises of this argument are more extensive than we have space to elaborate, but for brevity’s sake consider the role of thought experiment in experiment design and the manner in which possibility of personal observation guides thought experiment and therefore the process of scientific rigor. Scientific discovery works and is of value, and since the assumption of persons is indispensable to scientific discovery then it is of value. Such reasoning persuasively underwrites the posit of persons, but it says nothing of their identity conditions.
quantifier? The simple answer is yes, if the domain contains a restriction for the class of persons. The answer is a little more complicated if we do not allow this simplification. Nagel, for instance, takes the extension of the term “I” to be exactly the brain of each individual. But we can consider a kind of Kantian argument that the notion of personhood is indispensable to our conception/knowledge of the world. Everything we know about about the world is filtered or mediated via our position in the world i.e. specified in relation to the type of entity we take ourselves to be. Hence any knowledge we have of the world is impossible without the supposition of personal identity. The premises of this argument are more extensive than we have space to elaborate, but for brevity’s sake consider the role of thought experiment in experiment design and the manner in which possibility of personal observation guides thought experiment and therefore the process of scientific rigor. Scientific discovery works and is of value, and since the assumption of persons is indispensable to scientific discovery then it is of value. Such reasoning persuasively underwrites the posit of persons, but it says nothing of their identity conditions.
Identity Conditions and Reductive Explanations
Quine’s doctrine of “no entity without identity” might be thought to apply here. So we should consider whether the physical and psychological criterions of personhood run afoul of certain counterexamples. We consider an argument by Williams to show that the continuity criteria are defeasible, and then argue that that this is no bar to ontological commitment.
Consider the idea that I enter into an experiment where a mad scientist (i) manipulates my memories successively with an increasing range of changes and (ii) exposes me to a constant stream of brutal and agonising pain. With each change of memory we observe that there is an interruption (of an increasing degree) to my psychological continuity, however the continuation of my pain seems to promote the intuition that “I” remain suffering. Like the Sorites paradox this leads from plausible premises to an absurd conclusion. No matter that disparity between my memories of who I am before I enter the experiment and who I am afterwards, we must conclude I am the same person who began the experiment. This is absurd, since by suitably extensive manipulation of my memories I can come to believe anything about my past, desires and ambitions. The idea coming out of this thought experiment is that the degree of psychological connectedness over moments varies with the “features” manipulated and the notion of which “features” are preserved is central to estimates of personal identity. In particular this is about the strength of feeling versus the import of “core” memories for establishment of personal identity. Hence in any estimate over whether “I” survive the scientist’s manipulations we might want to draw a line; ranking how the intensity and duration of my pain versus the importance of some “crucial” sense of self-identity based on memory, fits into a categorical description of who I am. This line is unavoidably arbitrary.
Questions about whether I survive can be asked at any stage in the process of the scientist’s manipulations, and not all stages will have a definite answer. But given the importance that the role of personal identity has in our conception of the world we cannot tolerate such agnosticism, hence Williams argues we are better off accepting that the referent of the term “I” is simply the brain of that individual, then no matter the range of psychology disparity at least we can answer the question positively. I survive the experiment; I am “a changed man” but ultimately the same person. However, the Sorites line of argument applies equally to this physical criterion. Imagine a science fiction case where we apply a Theseus’ ship scenario by swapping out my body parts 1% at a time while maintaining the constant sense of pain. William’s absurd conclusion follows again. Hence we cannot simply take refuge in the notion that the brain is to be identified with our personhood. The sum of arguments seems to suggest that there is no fixed criterion of personal identity. Do you then follow Quine and claim there are no such entities? Or revert to Cartesian metaphysics?
Neither, we reject Quine’s doctrine and deny the Cartesian cosmos. We accept a form of reductionism where personhood supervenes on the physical and psychological facts and we allow that changes in the latter amounts to changes in the former, but feel no need to overly specify what particularities constitute our personhood at any particular moment. Contextual considerations about the phenomenal experience of self (and indeed other) will be our best guide to determine the weight of the particular psychological or physical features on which personal identity supervenes. We are ontologically generous but ultimately undogmatic in self description. Similarly we could generalize this view and say that personhood is property of objects that can be seen to supervene on a host of more primitive conditions e.g. say  \leftrightarrow M(x))") , where M is the property of being a moral agent, we could allow a reductive analysis of personhood in terms of moral agency. In this instance the right kind of continuity would be the history of the individual’s moral action and inaction. In this way I reject the idea that personal identity is suitably defined by straightforward physicalist reductions, and allow that personal identity can evolve in various ways. For Parfit personal identity is tied to the relation R of psychological/physical continuity, but I simply allow the key notion is the reduction applied and the reference of the term “I” is contextually individuated by the relation of reduction we appeal to in each scenario. We motivate a generous interpretation of by means of pragmatic considerations about the point of such an ontological posit, in the role of various explanatory projects.
, where M is the property of being a moral agent, we could allow a reductive analysis of personhood in terms of moral agency. In this instance the right kind of continuity would be the history of the individual’s moral action and inaction. In this way I reject the idea that personal identity is suitably defined by straightforward physicalist reductions, and allow that personal identity can evolve in various ways. For Parfit personal identity is tied to the relation R of psychological/physical continuity, but I simply allow the key notion is the reduction applied and the reference of the term “I” is contextually individuated by the relation of reduction we appeal to in each scenario. We motivate a generous interpretation of by means of pragmatic considerations about the point of such an ontological posit, in the role of various explanatory projects.
Why Identity is not what Matters
Identity doesn’t matter because it’s never been fixed anyway; physical/psychological continuity tolerate interruption and change.To see this reconsider the teleportation thought experiment re-jigged.
Instead of materializing at one location, let there be two pods in which two individuals appear both psychologically continuous with me but in different scenic locales. As before, the initial traveller dies from massive radiation exposure but my psychological concerns continue unabated in the two agents 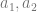 physically identical. Now if Identity matters then it is crucial that we are able to say (a) if I survived and (b) whether I am
physically identical. Now if Identity matters then it is crucial that we are able to say (a) if I survived and (b) whether I am 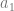 or
or 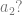 The defender of the claim that identity matters will be hard pressed to pick (b) whether I survived as either or
The defender of the claim that identity matters will be hard pressed to pick (b) whether I survived as either or 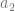 and such an inability casts doubt on (a) whether I survived at all. But since it is possible that psychological continuity can be (mildly) interrupted without impacting our attributions of personal identity, this fictional scenario of division poses a genuine problem for the identity theorist. For the reductionist, the question of my survival is vacuous. All that can be said is what the thought experiment describes; my physical and psychological state of existence ended, and then continued anew albeit doubly instantiated. We know all that happened. The identity theorist seems to hanker like the Cartesian dualist for a bigger answer, an essential character trait preserved over only the true “me” – but this is a misplaced metaphysical instinct.
and such an inability casts doubt on (a) whether I survived at all. But since it is possible that psychological continuity can be (mildly) interrupted without impacting our attributions of personal identity, this fictional scenario of division poses a genuine problem for the identity theorist. For the reductionist, the question of my survival is vacuous. All that can be said is what the thought experiment describes; my physical and psychological state of existence ended, and then continued anew albeit doubly instantiated. We know all that happened. The identity theorist seems to hanker like the Cartesian dualist for a bigger answer, an essential character trait preserved over only the true “me” – but this is a misplaced metaphysical instinct.
You might object that this doubling of “self” does not fit the logic of an identity relation, so there is a structural flaw in the thought experiment. It is no longer about personal identity but personal “possession”. In the scenario I can be seen as a virus inhabiting bodies not my own. Or put another way, the relation of identity should be one to one, so as to disallow branching instances of psychological continuity. Parfit responds, that if this concern is valid then the one to one feature of the personal identity relation must add something significant to the notion of personal identity over and above the instantiation of “mere” continuity. In this respect we could try to imagine possible scenarios wherein we place my two dopplegangers, and a third clone created by a teleportation device which only copies one instance of who I am (i.e. ensures that the relation is one to one). Given their identical psychological and physical traits each of the three is modally and behaviorally indistinguishable from the other, so what has the insistence on a one to one relation achieved? Nothing. Our constantly novel subjective experience preserves enough of our past concerns and traits to establish the strong connectedness and continuity that the attribution of personal identity aims to pick out. Nothing more need be added.
Identity does not matter because death by teleportation is not qualitatively different from ordinary survival. At worst it’s like a short nap. If you can be recognized (and recognize yourself) before and after bed, by any criteria whatsoever, then the same is true of teleportation. This is in a effect a concession that the relation of personal identity is founded on a non-strict, or contingent and evolving series of reductive self-interpretations.
Conclusions: What does matter?
Parfit’s breadth of thought on this topic is vast and we’ve only really glossed the crucial arguments. That said, this is a fair presentation of the argumentation, and I take it to have established the idea that the (1) persons are not Cartesian egos, (2) the existence of persons is a well motivated existential posit, (3) the existential claims can be defended by the establishment of particular supervenience relations which trace the evolution of appropriate features. Or put more formally we could say that the intensional semantics for “I” picks out at each context, one of a class of candidate reductions, (4) the domain of is best seen to be evolving in so far as the semantics of “existence” will not be settled until everything dies, (5) the attempts to undermine the variety of reductionist cases by arguments for the determinacy of identity are insufficient, hence do not pose a problem for our tolerance of multiple explanatory relations.
It remains to suggest (6) that there are practical reasons for maintaining an ontology rich with indistinct persons. Unfortunately, the scope of these considerations are vast and depend upon details of moral theories. It will suffice for the moment that these arguments for the existence and specific character of persons liberates us from a conception of selves which have an inordinate focus on the importance for self-concern. For instance, moral theories of self-interest are placed on a much weaker footing since the interests of each person is not necessarily preserved over future and successive stages of the individual agents involved. We will return to consider the details of developing these concerns in a later post. An alternative argument (7) for this characterization of persons is that the role of explanation can be expanded to incorporate multiple reductive relations which track different properties as appropriate to the type of personal identity we wish to track. This is more faithful to the variety of explanatory projects which seek to use the notion of persons as fundamental. For instance, the explanation of personal responsibility is best sought by incorporating the expectation of free action in the psychological/moral characterisation of that person, whereas the explanation of innocence by reason of insanity might better appeal to the causal/deterministic characterisation of the person as the locus of certain inviolate physical processes. The ontological structure we have articulated allows us to incorporate this flexibility and does so in a principled manner sympathetic to the projects of Parfit and McDaniels.
* Our discussion of the existential quantification is deeply indebted to Kris McDaniel’s paper on “Ways of Being” in the Metametaphysics collection
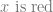

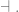
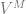



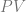
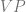
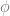




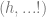
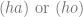
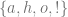




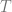
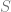
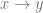


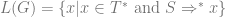
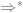

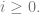
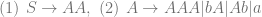
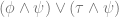
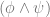




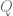

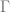
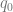

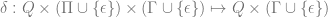
![< [ x ], y, z, w ... >](https://s0.wp.com/latex.php?latex=%3C+%5B+x+%5D%2C+y%2C+z%2C+w+...+%3E&bg=ffffff&fg=666666&s=0&c=20201002)
![< [y], z, w ... >](https://s0.wp.com/latex.php?latex=%3C+%5By%5D%2C+z%2C+w+...+%3E&bg=ffffff&fg=666666&s=0&c=20201002)
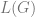
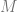



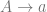
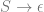


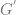

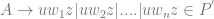

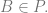

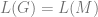
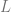
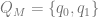
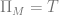
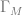

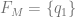
![\delta(q_{0}, a, \epsilon) = \{[q_{1}, w ] \text{ : } S \rightarrow aw \in P \}](https://s0.wp.com/latex.php?latex=%5Cdelta%28q_%7B0%7D%2C+a%2C+%5Cepsilon%29+%3D+%5C%7B%5Bq_%7B1%7D%2C+w+%5D+%5Ctext%7B+%3A+%7D+S+%5Crightarrow+aw+%5Cin+P+%5C%7D&bg=ffffff&fg=666666&s=0&c=20201002)
![\delta(q_{1}, a, A) = \{ [q_{1}, w] \text{ : } A \rightarrow aw \in P \text{ and } A \in N - \{S\} \}](https://s0.wp.com/latex.php?latex=%5Cdelta%28q_%7B1%7D%2C+a%2C+A%29+%3D+%5C%7B+%5Bq_%7B1%7D%2C+w%5D+%5Ctext%7B+%3A+%7D+A+%5Crightarrow+aw+%5Cin+P+%5Ctext%7B+and+%7D+A+%5Cin+N+-+%5C%7BS%5C%7D+%5C%7D+&bg=ffffff&fg=666666&s=0&c=20201002)
![\delta(q_{0}, \epsilon, \epsilon) = \{ [q_{1}, \epsilon] \} \text{ if } S \rightarrow \epsilon \in P](https://s0.wp.com/latex.php?latex=%5Cdelta%28q_%7B0%7D%2C+%5Cepsilon%2C+%5Cepsilon%29+%3D+%5C%7B+%5Bq_%7B1%7D%2C+%5Cepsilon%5D+%5C%7D+%5Ctext%7B+if+%7D+S+%5Crightarrow+%5Cepsilon+%5Cin+P&bg=ffffff&fg=666666&s=0&c=20201002)
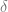

![[q_{0}, u, \epsilon] \vdash [q_{1} \epsilon, w]](https://s0.wp.com/latex.php?latex=%5Bq_%7B0%7D%2C+u%2C+%5Cepsilon%5D+%5Cvdash+%5Bq_%7B1%7D+%5Cepsilon%2C+w%5D+&bg=ffffff&fg=666666&s=0&c=20201002)

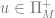
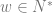
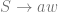

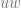

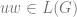
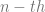
![[q_{0}, u, \epsilon ] \vdash^{n} [q_{1}, \epsilon, w]](https://s0.wp.com/latex.php?latex=%5Bq_%7B0%7D%2C+u%2C+%5Cepsilon+%5D+%5Cvdash%5E%7Bn%7D+%5Bq_%7B1%7D%2C+%5Cepsilon%2C+w%5D&bg=ffffff&fg=666666&s=0&c=20201002)
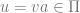
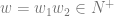
![[q_{0}, va, \epsilon] \vdash^{n-1} [q_{1}, a, Aw_{2}] \vdash [q_{1}, \epsilon, w_{1}w_{2}]](https://s0.wp.com/latex.php?latex=%5Bq_%7B0%7D%2C+va%2C+%5Cepsilon%5D+%5Cvdash%5E%7Bn-1%7D+%5Bq_%7B1%7D%2C+a%2C+Aw_%7B2%7D%5D+%5Cvdash+%5Bq_%7B1%7D%2C+%5Cepsilon%2C+w_%7B1%7Dw_%7B2%7D%5D&bg=ffffff&fg=666666&s=0&c=20201002)
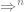
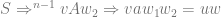

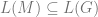

 , effecting a series of read, write actions to end with the output value of
, effecting a series of read, write actions to end with the output value of 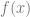 thereby simulating the mathematical function naturally described by
thereby simulating the mathematical function naturally described by  .
. for all
for all 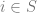 , where
, where 
 if, else, goto, stop
if, else, goto, stop
 . Each of these variables can be set to have have values in the natural numbers, and it is in this manner that we expect our machine to operate on a string of variables. Once the appropriate variables have been “initialized” then our program can begin. Which programs you ask?
. Each of these variables can be set to have have values in the natural numbers, and it is in this manner that we expect our machine to operate on a string of variables. Once the appropriate variables have been “initialized” then our program can begin. Which programs you ask?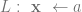
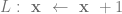
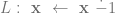
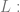 stop
stop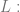 if
if 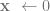 goto
goto 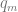 else goto
else goto 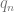
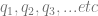 until either the program stops, or a new program begins because we have switched machine states. A machine state is a program which enacts an algorithm on particular initialised variables.
until either the program stops, or a new program begins because we have switched machine states. A machine state is a program which enacts an algorithm on particular initialised variables.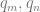 exceed
exceed  the program for the stop command. In traditional Turing machines the add and proper subtraction functions could be simulated by erasing and printing additional numbers onto the input/output tape so as to alter the number coded, for instance, in Wang’s binary notation. The current method is more perspicuous and less arduous to depict.
the program for the stop command. In traditional Turing machines the add and proper subtraction functions could be simulated by erasing and printing additional numbers onto the input/output tape so as to alter the number coded, for instance, in Wang’s binary notation. The current method is more perspicuous and less arduous to depict. to the final state
to the final state 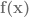 , the result of applying
, the result of applying 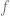 to
to  is an abbreviation for X followed by
is an abbreviation for X followed by  , then…
, then…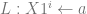 has the code
has the code 
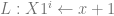 has the code
has the code 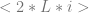
 has the code
has the code 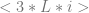
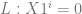 goto
goto 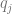 has the code
has the code 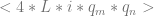
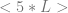
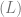 in the program the instruction defines, and the precise change (
in the program the instruction defines, and the precise change (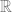 as those primitive recursive functions
as those primitive recursive functions 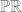 closed under the operations of unbounded search. We now consider another definition which allows us to illustrate the relation between formal logic and recursion theory. Better, it allows us to set the scene for how definability in first order logic corresponds to enumerability of a recursive function.
closed under the operations of unbounded search. We now consider another definition which allows us to illustrate the relation between formal logic and recursion theory. Better, it allows us to set the scene for how definability in first order logic corresponds to enumerability of a recursive function. for a given first order definable relation
for a given first order definable relation 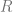 , we say that the characteristic function works like a test for membership of the class
, we say that the characteristic function works like a test for membership of the class  in our first order universe when it returns true if
in our first order universe when it returns true if 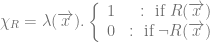
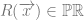 then we have
then we have 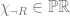 since
since  which is in the set
which is in the set 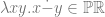
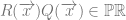 , then pick
, then pick 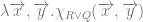 as defined:
as defined: 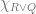
 , which is clearly in
, which is clearly in  . Assume
. Assume 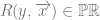 and let
and let 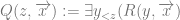 , then the idea is to define a search which seeks “upward” towards z to determine at which point the relation
, then the idea is to define a search which seeks “upward” towards z to determine at which point the relation  holds? We define the recursion equation as follows: First not that
holds? We define the recursion equation as follows: First not that 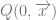 is always false since 0 is not strictly greater than any natural number. So…
is always false since 0 is not strictly greater than any natural number. So…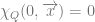
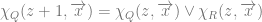
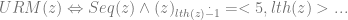 Penultimate Step encodes a halt …
Penultimate Step encodes a halt …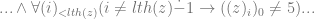 None but the penultimate step encodes halts}
None but the penultimate step encodes halts}
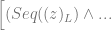 Every program is the result of a sequence of actions, and…
Every program is the result of a sequence of actions, and… Either L initialises variables, switches to L+1 or…
Either L initialises variables, switches to L+1 or…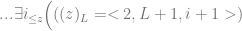
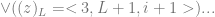 it adds or subtracts 1, switches to L+1 …
it adds or subtracts 1, switches to L+1 …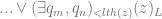
![= <4, L+1, i+1, q_{m+1}, q_{n+1} > \Big) \Big) \Big]](https://s0.wp.com/latex.php?latex=%3D+%3C4%2C+L%2B1%2C+i%2B1%2C+q_%7Bm%2B1%7D%2C+q_%7Bn%2B1%7D+%3E+%5CBig%29+%5CBig%29+%5CBig%5D&bg=ffffff&fg=666666&s=0&c=20201002) … or changes program within the parameters of the halting condition.
… or changes program within the parameters of the halting condition.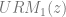 denote the code of the abstract machine with one free variable. In short, we want to define a first order relation like:
denote the code of the abstract machine with one free variable. In short, we want to define a first order relation like: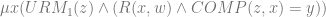
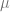 -recursion. We shall prove this another time. The key point of interest is that we have shown that all abstract machines can be expressed as recursive functions.
-recursion. We shall prove this another time. The key point of interest is that we have shown that all abstract machines can be expressed as recursive functions.