“Clowns to the left of me, jokers to the right…It’s so hard to keep a smile from my face.”
In this post we will (a) prove the squeezing theorem about the limits of functions, and (b) then examine Kriesel’s Squeezing argument for the intuitive notion of logical validity. The goal will be assess the manner in which such arguments lend exactitude to imprecise intuitions. The hope is that using a squeezing argument we may be able to provide a general method for making a vague notion mathematically concrete. We will show the whole issue turns on what counts as “vague”.
The Squeezing Theorem:
We wish to prove, that if
![[; \lim_{x \to x_{0}} f(x) = A \wedge \lim_{x \to x_{0}} g(x) = A ;]](https://i0.wp.com/www.codecogs.com/gif.latex "\lim_{x \to x_{0}} f(x) = A \wedge \lim_{x \to x_{0}} g(x) = A")
and we have
then we have it that
This theorem can be best be envisioned by thinking of two policemen escorting a rowdy prisoner into a jail cell. No matter how wildly the prisoner bucks, if the two policemen end up in the jail cell so too will the prisoner they’ve escorted there. In other words, no matter how unpredictable the movement of , we may chart the trajectory of the function if it’s action can be constrained the operations of two other functions .
This theorem makes a vague function more precise and mathematically tractable. We now prove it to be valid.
The Proof
From our our first assumption we know that
Consider that we also so know that any value of falls between the values of . So we may attempt to prove that we can find a such that
But since it follows that:
.
Let . Now pick any distance measure [; \epsilon ;] and we can see that
because we know from our first assumption that fall within any [; \epsilon ;]-measure whatsoever. So it follows directly by the transitive property of inequality that:
as desired. So we have can conclude
.
The Squeezing Argument
The proof we just performed demonstrates a method by which we can observe an increased exactitude in our assessment of a previously unknown parameter. The question remains; can we use such a method outside of mathematics to minimize imprecision in other domains? Consider an argument from Kriesel to the effect that the “intuitive notion of validity” is appropriately isolated as a property of all and only those arguments which are provably valid within a proof system, that may (in turn) be modeled in a Tarski style truth functional semantics. The idea is that we can use these two formal notions of syntactic and semantic validity to sandwich the intuitive notion of intuitively valid inference. So like the drunk between two policemen, all those conclusions arrived at by our “formal” notions of valid inference ought to be held as valid intuitively too.
The argument proceeds as follows: Take your intuitive notion of valid inference, imagine your favorite instances of a valid arguments and note that they seem to be true in virtue of their form alone e.g [; (\phi \rightarrow \psi), \phi \vdash \psi ;]. That is to say that no matter the nature of the premises, if we substitute them uniformly into positions in our favorite argument, then we will have a new valid argument.
We’ve cheated here a little bit by representing your favorite argument (Modus Ponens) schematically in the notation for propositional logic. But this move is tolerable in that it points to an intuitive notion of “valid in virtue of form” without strictly defining it. We could also simply have said that:
[; \text{ If } \psi \text{ follows from } \phi \text { and } \phi \text{ is true, then } \psi \text{ is true too whatever the values of our propositions } ;]
We claim that [; \psi ;] is validly concluded from our premises simply by the form of the argument. The notion is deliberately somewhat vague, since we’ve have made no effort to clarify validity or form…but the squeezing argument aims to show that we don’t need a more exact clarification because we can find equivalent notions of validity which circumscribe what it would mean to say that an argument is “valid in virtue of form.”
Syntactic Pressure
On the one hand we find the standard proof theoretic notion of validity, where an argument is conducted in, for instance, a natural deduction system which has very precise rules on what counts as a valid conclusion from any set of premises whatsoever. These rules govern the syntactic manipulation of the sentences in a formal language [; \mathbb{L} ;]. For instance reasoning from conjunctive claims has very precise behavior determined by two syntactic rules:
[; \dfrac{\phi_{1} \& \phi_{2}}{\phi_{i}} \& E \text{ and } \dfrac{\phi_{1}, \phi_{2}}{\phi_{1} \& \phi_{2}} \& I ;]
These rules are called introduction and elimination rules the conjunction operator. Similarly, we have rules governing conditional reasoning:
[; \dfrac{(\phi \rightarrow \psi), \phi }{\psi} \rightarrow E \text{ and } \dfrac{ | \phi | …… \psi}{ \phi \rightarrow \psi} \rightarrow I ;]
The behavior of [; \& ;] shouldn’t need any explanation, and [; \rightarrow E ;] is just modus ponens, but [; \rightarrow I ;] is more interesting. This rule states that if we assume [; \phi ;] and in the course of syntactically manipulating our premises we arrive at [; \psi ;] we may conclude [; \phi \rightarrow \psi ;]. Putting this together we can construct the following argument.
- [; | \phi \& \psi | ;] Assumption
- [; \phi ;] by &E, (1)
- [; \psi ;] by &E, (1)
- [; \psi \& \phi ;] by &I, (2), (3)
- [; (\phi \& \psi) \rightarrow (\psi \& \phi) ;] by →I (1), (4).
This argument proves that conjunction is order invariant with intuitively acceptable rules of premise manipulation. As such, we wish to say that the argument is also valid in virtue of form, since regardless of the nature of our premises the syntactic rules would apply. It is our acceptance of these arguments that allow us to construct the soundness proof for classical logic. The proof is by induction on the length of any argument constructed in the classical system. For an argument of any length each step proceeds by an application of an intuitively acceptable rule, so if the argument is syntactically correct we must accept the conclusion of the argument as intuitively sound too since we can’t fault any step in the reasoning. On this basis Kriesel asks us to accept the claim that:
If [; X \vdash_{nd} \phi ;] then [; \phi ;] follows in virtue of form from the premises X.
In words, the claim states that if the conclusion is a valid consequence of the premises X in our natural deduction system then we may also say that the conclusion is intuitively valid too.
Semantic Pressure
From the other direction we build models and specify precise criteria for when a claim is true on a model. Again we take the formal language [; \matthbb{L} ;] and specify rules for evaluating claims constructed in the language. So on a model [; M ;] we would say that [; M \models \phi ;] holds whenever the state of affairs [; ||\phi || ;] exists in the model. So if [; \phi ;] describes the angle of a building in our model, then [; \phi ;] is said to be true just when the building is angled as described. False otherwise. We build up the semantic definition to incorporate the syntax of [; \mathbb{L} ;]. In particular we have:
- [; M \models \phi \& \psi \Leftrightarrow || \phi || \in M \text{ and } || \psi || \in M ;]
- [; M \models \phi \rightarrow \psi \Leftrightarrow || \phi || \not\in M \text{ or } || \psi || \in M ;]
On this understanding we can construct and evaluate arguments as valid only when their is no interpretation of the model that could make the premises true and the consequence false. Intuitively this means, an argument is valid just when there is no way of evaluating the premises and falsifying the conclusion. So whether [; \phi \& \psi ;] is true or false in the model, if we assume it’s true we ought to be able ensure the [; \psi \& \phi ;] is true too. More particularly we must be able to conclude that [; M \models \phi \& \psi \rightarrow \psi \& \phi ;] . If the antecedent is true in the model this is obvious from the semantic definition of [; \& ;], but if the antecedent is false, the claim is vacuously true and holds. So for whatever the evaluation of the particulars the argument holds, and hence the semantics of [; \& ;] is order invariant.
Now since an argument with true premises and a false conclusion can’t be valid, never mind valid in virtue of the form, we can see that:
[; \text{ If } M \nvDash \phi \text{ then } \phi \text{ does not follow validly in virtue of form from any premise set describing } M ;]
By the contraposition of this claim it follows that any argument valid in virtue of form derived from the premises describing M will be semantically valid in the model M.
Tidying Up
So we have already observed that the set of syntactically valid conclusions are all intuitively valid in virtue of their form, and we have just seen that any intuitively valid argument can be modeled semantically. More visually we have the following situation
[; Syn = \{ X, \phi | X \vdash_{nd} \phi \} \subseteq Int = \{ X, \phi | \phi \text{ intuitively follows from } X \} \\ \subseteq Sem = \{X, \phi | X \vDash \phi \} ;]
But by the completeness theorem for classical logic we know that [; Syn = Sem ;]. So we now know that
[; Syn = Int = Sem ;]
which ensures that the vague intuitive notion of “valid in virtue of form” is coextensive with two mathematically precise notions of validity.
The Crucial Step
The use of the soundness proof is a good motivation for this argument as syntactic validity lends some substance to the informal notion of formal validity. But we can imagine a case where a non-classical logician could argue similarly so long as they can prove a soundness result on some non-classical model. However, the non-classical logician will still need to avail of a meta-level conditional operator which preserves the validity of contraposition if they are to argue as above that semantic validity also constrains intuitive validity. It would be strange, but possible to argue that the intuitive notion of validity was coextensive with a definition of logical validity that did not preserve contraposition, while informally availing of it.
This hints at the idea that “intuitive validity” can be squeezed between a number of different consequence relations, and the manner in which we squeeze depends wholly on how we specify the meanings of the logical connectives (i.e &, →, etc ) governing those relations. Either syntactically or semantically there are a number of candidate options such as intuitionistic and relevantist logics. None is obviously more accurate as a representation of the colloquial notion of validity, so the degree to which a Squeezing argument is strictly and mathematically compelling depends on how appealing you find the characterization of soundness. For better or for worse our estimation of whether an inference is sound seems to depend to a degree on the context in which the inference is made. In this manner our intuitive notion of validity should be expected to fluctuate. However, the squeezing argument ensures that notion of contextual validity can be made precise with a little patience.
Can we make a general class of Squeezing theorems?
Peter Smith argues in favor of this notion so long as the first step on the route to generating a Squeeze theorem renders the “vague” candidate clear in some specific sense. So the notion of computability, like the notion of validity has an intuitive reading which can be made slightly more precise by an appeal to specific examples or a generic gloss. The use of these examples allows us to find general formal notions of computability, validity which capture the paradigm examples. In this manner we move along a trajectory of conceptual sophistication aiming for an increased exactitude. In the next few posts we’ll assess Smith’s argument to effect that Squeezing arguments can be used to establish a proof of the Church-Turing thesis.

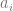



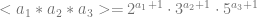




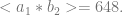
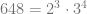

[Sequence Number]
[Length]
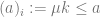
[Decoding]
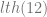

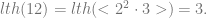

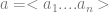
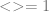












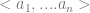




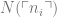

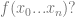 The answer is
The answer is 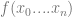 can be found in finitely many steps. An intuitively
can be found in finitely many steps. An intuitively  if there is a procedure for determining the value. Specifically, a procedure enacted by the performance of a sequence of the
if there is a procedure for determining the value. Specifically, a procedure enacted by the performance of a sequence of the 


 such that
such that 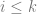 . Think of these as selective maps between a set of inputs and a particular output.
. Think of these as selective maps between a set of inputs and a particular output. are functions, then [; f(g) = h ;] is a function. The primitive functions are those created by applications of composition on the initial functions.
are functions, then [; f(g) = h ;] is a function. The primitive functions are those created by applications of composition on the initial functions.

 then we can pick a function
then we can pick a function 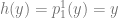 and another function
and another function 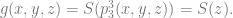 Now we define as follows:
Now we define as follows: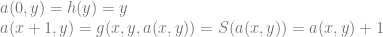
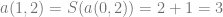 . Hopefully, you agree this is correct, if not you should probably stop reading.
. Hopefully, you agree this is correct, if not you should probably stop reading.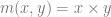 and take the following functions
and take the following functions  ,
, 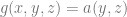 , then we can note that:
, then we can note that: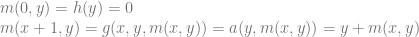
 The idea should be becoming clear by now. The sequential operation of the recursive formulation allows us to establish a well defined composition operation iteratively as we ascend through the natural numbers.
The idea should be becoming clear by now. The sequential operation of the recursive formulation allows us to establish a well defined composition operation iteratively as we ascend through the natural numbers.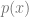 having natural numbers as coefficients is primitive recursive. Any such function
having natural numbers as coefficients is primitive recursive. Any such function  performs an unbounded search on the variable
performs an unbounded search on the variable  , just in case for all
, just in case for all 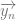 the following holds:
the following holds: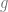 :
: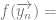
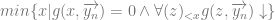

 which performs a search to find the minimal free element which satisfies the function
which performs a search to find the minimal free element which satisfies the function 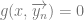 , where the function is also defined for values less than
, where the function is also defined for values less than 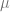 -recursion:
-recursion: ![\mu x [G(x, y_{1} ... y_{n})]](https://s0.wp.com/latex.php?latex=%5Cmu+x+%5BG%28x%2C+y_%7B1%7D+...+y_%7Bn%7D%29%5D&bg=ffffff&fg=666666&s=0&c=20201002) With this addition we have may step through the natural numbers until we find an appropriate sequence which satisfies our condition. So for any condition which we could define on the primitive recursive functions, we can effect a search of the function space to determine which, (if any) is the minimal point at which our condition is satisfied. This doesn’t change the general observation that primitive recursive procedures surely map to effectively calculable problems, it only adds flexibility to how we apply our recursive procedures since we can now specify algorithmic operations to kick into effect at selective stages in our function space.
With this addition we have may step through the natural numbers until we find an appropriate sequence which satisfies our condition. So for any condition which we could define on the primitive recursive functions, we can effect a search of the function space to determine which, (if any) is the minimal point at which our condition is satisfied. This doesn’t change the general observation that primitive recursive procedures surely map to effectively calculable problems, it only adds flexibility to how we apply our recursive procedures since we can now specify algorithmic operations to kick into effect at selective stages in our function space. is recursive then
is recursive then 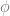 represents an effectively calculable method on our problem space.
represents an effectively calculable method on our problem space.