Have you ever been introduced to too many people at a party and come up with ad hoc nicknames, to keep track of who they were, how they knew the host etc? If so, congratulations you’ve successfully invented a coding schema.
Now imagine a party at Hilbert’s hotel with all its infinite guests. Suppose that each night they form a congo line alternating positions at random each night. It’s your task to keep track of the order of who follows who, but given that you can’t remember all their names you try to come up with a coding scheme which would uniquely identify each individual in the line… unfortunately the line is not finite, so you’ll need an infinite set of codes to describe the order of the line:
It’s at this point you might think of trying to number them. Only a moment later you realise how convenient this procedure is; after all an infinite of people can be labeled by an infinity of numerals! Call a congo line a sequence 
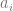
We will consider a coding technique invented by Godel. The approach uses the fact that there are an infinity of primes to name the infinity of congo dancers. So for example we might specify the first dancer 

In this instance we characterize each line as the product of the labels of the dancers. We let the empty sequence
- etc, etc…

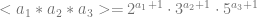
But this doesn’t make much sense; how can we add or multiply dancers? Not obviously. However we could begin by categorizing types of dancers as graceful, quick, sultry, smooth, etc, then we can assign each type a distinct number, so the coding maps each type into a region of primes determined by the type of dancers in the sequence, thereby allowing us to represent each congo line as a chain of prime numbers with each member “scored” according to their type. Allow that we have a (in)finite alphabet of types, we say the types are coded as follow
- #
- #
- #
- … associated with as many code numbers as required.



Now that we have named the parts, we might want to name the whole line. So we need to find a unique label for any sequence of dancers. We achieve this by multiplying the primes to determine a unique number for a sequence of any length, since each dancer has unique label each product will be unique. Hence, any numeral names a unique object, whether it be a sequence of dancers or a lonely dancer. So we can see that
#

More succinctly, we could say:
#
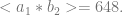
We need to do a little more work to show that this labeling system will allow us to recover the structure of each congo line by decoding. But of course all we need to do here is perform a prime factorisation, from which it is straightforward to recover that 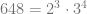
Talking about dancing
We can now define several functions which will help us talk about dancing. Firstly we describe our congo line as a sequence, as only lines with this property are encoded by the prime-coding technique we used above. The following definitions apply to sequence numbers only. But they’re pretty straightforward. You might want to describe the length of a congo line, or recover the participants from the #name we have given the line, and we can do this with the following function. Let 
[Sequence Number]
[Length]
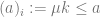
[Decoding]
So let’s see how the length of a string can be recovered. From any number #(a) we have its prime factorisation, so the trick to decomposing each element in the factorisation, for instance take 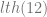

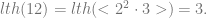

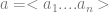
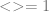
Similarly, we check 









Talking about anything else.
So far we have suggested that we could use this coding technique to simplify discussions about congo lines, but this is merely one application. In fact the prime-coding technique is versatile enough to encode any structure. In particular we shall come to see how it can effectively encode sentences of the rich logical language 

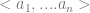

This utility allows us to express claims about the object 


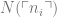

The generality of this technique is truly staggering once you perceive it. Any language, or system capable of identifying the natural numbers can use the prime coding technique to code its own expressions is then capable of expressing claims about its own syntax. Allowing the expression of a “meta-level” reflection about the properties of any constructions developed within our own language. Constructions such as novels, poems and proofs – some of which are certainly nice.
This expressivity allows for Godel’s famous incompleteness result; about which, more later.
