Introduction: Characterising Semantic Content
The fundamental semantic unit on Brandom’s picture of semantics is that of the vocabulary. Opposed to traditional accounts of semantics which seek to analyse of the meaning of statements by breaking-down the semantic structures into discrete semantic units, Brandom allows (in his Between Saying and Doing) that vocabularies exist as self-sustaining structures, that do not admit such absolute decomposition. In support of the view he points to the failure of the logicist program in the philosophy of mathematics, where the robust vocabulary of mathematics cannot be semantically equated with statements expressible in purely logical vocabulary.
He further defends the general claim that the traditional project of semantic analysis is misguided by Sellarsian arguments against the myth of the given. Any candidate analysis will involve a decomposition of the whole structure into some primitive semantic units in the base vocabulary. The traditional empiricist program would seek to analyse all semantic understanding in terms of understanding primitive observational reports. So assuming that some form of empiricism is true, then some base observational reports are semantically autonomous of the broader vocabulary. The broader vocabulary depends for its semantic cogency on the empiricist’s autonomous base, in terms of which the it is to be analysed. However, for any candidate base vocabulary we can argue that we cannot be deemed to understand the semantic primitives unless we know how they are to be practically deployed within the network of our broader vocabulary. For example, assume the empiricist wants a reduction of our knowledge into a base phenomenalist observational vocabulary. How can we be considered to understand the claim that: 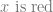

On this understanding the meaning of any syntactic constructions are to be understood relative to the knowledge of a broader vocabulary, and we demonstrate the understanding of a vocabulary by our ability to enter into certain kinds of practices. In mathematics, for instance, we can be said to know the meaning of the term “proof” only when we inferentially trace the path from our assumptions to the statement we set out to prove and subsequently react appropriately to the statement of a proof completion 
He further notes that where we have access to meta-vocabulary 



The thought is that for any particular vocabulary 
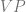
Intuitive Sellarsian Examples
To illustrate the types of considerations this set up allows, we examine another Sellarsian argument. Namely, the claim that the “looks-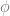

Again we denote the composition relation by the dashed arrow, but the point is clear, since the expression of perceptual modalities requires the ability to practically distinguish objects by sight accurately. It is a necessary condition of such an ability that we are able to identify things in their actual condition, which is a ability sufficient to confer meaning on existential and identity claims. Hence, talk of appearance amounts to the withholding of the existential claim, and only by composing our abilities can we generate a suitably expressive language to capture the perceptual modalities. Similarly, the argument we sketched above, that there is no autonomous observational vocabulary from which we build our semantics relies on the idea that observational expression assumes a practical capacity that in turn presupposes the inferential capacity (which is at least sufficient) for an appropriately broad semantic understanding, contrary to the supposed semantic autonomy of observational reports. Only by composing the two abilities can we determine a language sufficient to articulate the conditions under which observational reports are meaningful.

Recall that the semantic understanding of the claim “x is red” requires the ability to not equate the object x with any blue object. In particular we must be able to wield an inferential capacity which gives the lie to the idea that we understand color observations independently of anything else.
Santa-Speak and Speaking about Santa-Speak
Now for a brief digression.
Santa laughs and he laughs heartily. We can build a machine which describes how Santa laughs, and it can be used to establish whether any program generating a laughter track appropriately simulates Santa’s laugh. The following example over and above the previous cases is of central significance, not just for its relative clarity but also because of how the setting has a connection to computational linguistics. The basic idea is that we take a set 

The rules are such that for any legitimate string of inputs Santa always laughs a string 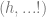
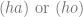
Relating Automata to Meaning Use Diagrams
The notion of producing a legitimate string is analogous to the notion of competent linguistic practice. In effect the rules of syntactic construction put forward in the state-table are a normative constraint on how deploy Santa’s alphabet 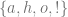

The ”meta-language” of the state-table (above) describes the practices appropriate for the proper syntactic representation of Santa’s laugh. The point is that if we can describe this kind of practical performance constraint we can specify the pre-conditions and post-conditions appropriate to render certain utterances “meaningful” or at least syntactically correct. One fine example of this trend is the manner in which recursive languages can be specified in a category free language, which in turn is demonstrably understood by an ability to deploy the differential response patterns of an appropriate push-down automata. Again the picture is as follows:

We shall now sketch the details that show this relation to describe a valid theorem.
Context Free Grammars
First recall that a context free grammar is a phase structure grammar 

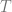

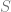
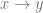


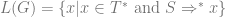
where 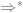

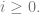
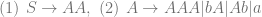
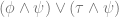
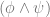



This point should illustrate how adherence to (and recognition of) these production rules is taken to be sufficient for an understanding of the language; more radically, Brandom wants to say that the practice of these rules confers legitimacy on strings created in the language. Like the Santa example above, we can create a machine to test whether any string is “grammatical” i.e. legitimate, on the basis of the definition of
You, me and Pushdown Automata
So who understands these languages? Or better said, what behaviour is indicative of this understanding, and who enacts it? Pushdown automata are machines with a virtual memory, like the Santa-speak finite state machine, but augmented with a memory stack.
Definition: Pushdown automata: are sextuples (
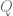

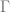
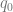

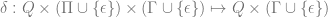
The thought is that a machine takes inputs of an ordered triple in the form the active machine state, memory and a given string read from left to right ![< [ x ], y, z, w ... >](https://s0.wp.com/latex.php?latex=%3C+%5B+x+%5D%2C+y%2C+z%2C+w+...+%3E&bg=ffffff&fg=666666&s=0&c=20201002)
![< [y], z, w ... >](https://s0.wp.com/latex.php?latex=%3C+%5By%5D%2C+z%2C+w+...+%3E&bg=ffffff&fg=666666&s=0&c=20201002)
So now the idea is to show that for every context free grammar 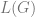
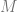


Lemma The Greibach Normal Form of a context free grammar

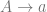
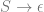
where 

There is an algorithm for converting all context free grammars 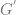

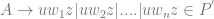

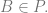

Theorem: For every CFG which generates
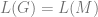
Proof Let 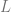
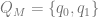
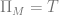
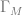

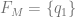
and we define the transition function as follows:
(1)
![\delta(q_{0}, a, \epsilon) = \{[q_{1}, w ] \text{ : } S \rightarrow aw \in P \}](https://s0.wp.com/latex.php?latex=%5Cdelta%28q_%7B0%7D%2C+a%2C+%5Cepsilon%29+%3D+%5C%7B%5Bq_%7B1%7D%2C+w+%5D+%5Ctext%7B+%3A+%7D+S+%5Crightarrow+aw+%5Cin+P+%5C%7D&bg=ffffff&fg=666666&s=0&c=20201002)
(2)
![\delta(q_{1}, a, A) = \{ [q_{1}, w] \text{ : } A \rightarrow aw \in P \text{ and } A \in N - \{S\} \}](https://s0.wp.com/latex.php?latex=%5Cdelta%28q_%7B1%7D%2C+a%2C+A%29+%3D+%5C%7B+%5Bq_%7B1%7D%2C+w%5D+%5Ctext%7B+%3A+%7D+A+%5Crightarrow+aw+%5Cin+P+%5Ctext%7B+and+%7D+A+%5Cin+N+-+%5C%7BS%5C%7D+%5C%7D+&bg=ffffff&fg=666666&s=0&c=20201002)
(3)
![\delta(q_{0}, \epsilon, \epsilon) = \{ [q_{1}, \epsilon] \} \text{ if } S \rightarrow \epsilon \in P](https://s0.wp.com/latex.php?latex=%5Cdelta%28q_%7B0%7D%2C+%5Cepsilon%2C+%5Cepsilon%29+%3D+%5C%7B+%5Bq_%7B1%7D%2C+%5Cepsilon%5D+%5C%7D+%5Ctext%7B+if+%7D+S+%5Crightarrow+%5Cepsilon+%5Cin+P&bg=ffffff&fg=666666&s=0&c=20201002)
These are sufficient because of the insistence on the Greibach normal form. The 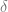

![[q_{0}, u, \epsilon] \vdash [q_{1} \epsilon, w]](https://s0.wp.com/latex.php?latex=%5Bq_%7B0%7D%2C+u%2C+%5Cepsilon%5D+%5Cvdash+%5Bq_%7B1%7D+%5Cepsilon%2C+w%5D+&bg=ffffff&fg=666666&s=0&c=20201002)

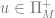
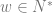
Our base case is the one step computation, and an application of the rule of the form 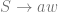
IH For all 
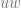

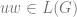
Now for the 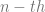
![[q_{0}, u, \epsilon ] \vdash^{n} [q_{1}, \epsilon, w]](https://s0.wp.com/latex.php?latex=%5Bq_%7B0%7D%2C+u%2C+%5Cepsilon+%5D+%5Cvdash%5E%7Bn%7D+%5Bq_%7B1%7D%2C+%5Cepsilon%2C+w%5D&bg=ffffff&fg=666666&s=0&c=20201002)
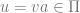
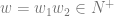
![[q_{0}, va, \epsilon] \vdash^{n-1} [q_{1}, a, Aw_{2}] \vdash [q_{1}, \epsilon, w_{1}w_{2}]](https://s0.wp.com/latex.php?latex=%5Bq_%7B0%7D%2C+va%2C+%5Cepsilon%5D+%5Cvdash%5E%7Bn-1%7D+%5Bq_%7B1%7D%2C+a%2C+Aw_%7B2%7D%5D+%5Cvdash+%5Bq_%7B1%7D%2C+%5Cepsilon%2C+w_%7B1%7Dw_%7B2%7D%5D&bg=ffffff&fg=666666&s=0&c=20201002)
By the inductive hypothesis and the Greibach production rules we have it that there is an 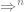
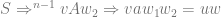

This shows that 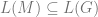
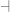
To see that the language
Automata, Differential Response and Algorithmic Elaboration
So we know that functional capacity with the procedures enacted by a PDA is sufficient to generate a veneer of competence with a recursive language. If all of this is beginning to sound like an agonisingly exact rendition of the Turing Test, rest assured that Brandom has something more in mind. Linguistic competence is only one criteria is any test for sapience. He writes:
The issue is whether whatever capacities constitute sapience, whatever practices or abilities it involves, admit of such a substantive practical algorithmic decomposition. If we think of sapience as consisting in the capacity to deploy a vocabulary, so as being what the Turing test is a test for, then since we are thinking of sapience as a kind of symbol use, the target practices-or-abilities will also involve symbols. But this is an entirely separate, in principal independent, commitment. That is why […] classical symbolic AI-functionalism is merely one species of the broader genus of algorithmic practical elaboration AI-functionalism, and the central issues are mislocated if we focus on the symbolic nature of thought rather than the substantive practical algorithmic analyzability of whatever practices-or-abilities are sufficient for sapience. (BSaDpg 77)
This is pregnant passage, but the key take away is that the conditions of sapience are unspecified, but taken to be specifiable by means of algorithmic action. Plausibly the conditions involve more than linguistic competence, but can nevertheless be described as certain kind of differential response to an array of stimuli a la Quine; where the input strings can be thought of as composed of as various information streams, and the transition functions are modeled on features of our cognitive processing. The view of AI-functionalism at the heart of this story is premised on the idea that certain algorithmically specifiable computer languages are apt to serve as pragmatic meta-vocabularies for our natural languages. As such, any pattern of differential response we care to mention can be specified algorithmically, if it can be discussed in natural language at all. Hence, whatever the future course of scientific discovery, so long as the conditions of sapience can be artificially implemented and described in natural language, we can develop an algorithmic elaboration of patterns of the differential response involved. So there is, in principal, no bar for the development of artificial intelligence, if we can come to understand what in fact makes us tick.
Before considering the wider ramifications of this view we shall examine (in the next post) a detailed example of an algorithmic elaboration of the abilities and practices deemed to be pragmatically sufficient to warrant ascriptions of linguistic competence. This will be paradigmatic for the broader stripe of “competency” claims Brandom needs to make if he is to isolate the conditions of sapience algorithmically.
